
Hi, working with clearml 1.6.4 what is the correct way to list all the dataset s within a specific project ?
3 years ago
Hi, How can I get the remote URI of a Dataset (assuming it is GS or S3). Do I need to combine the get_default_storage() with something? Since some datasets a...
3 years ago
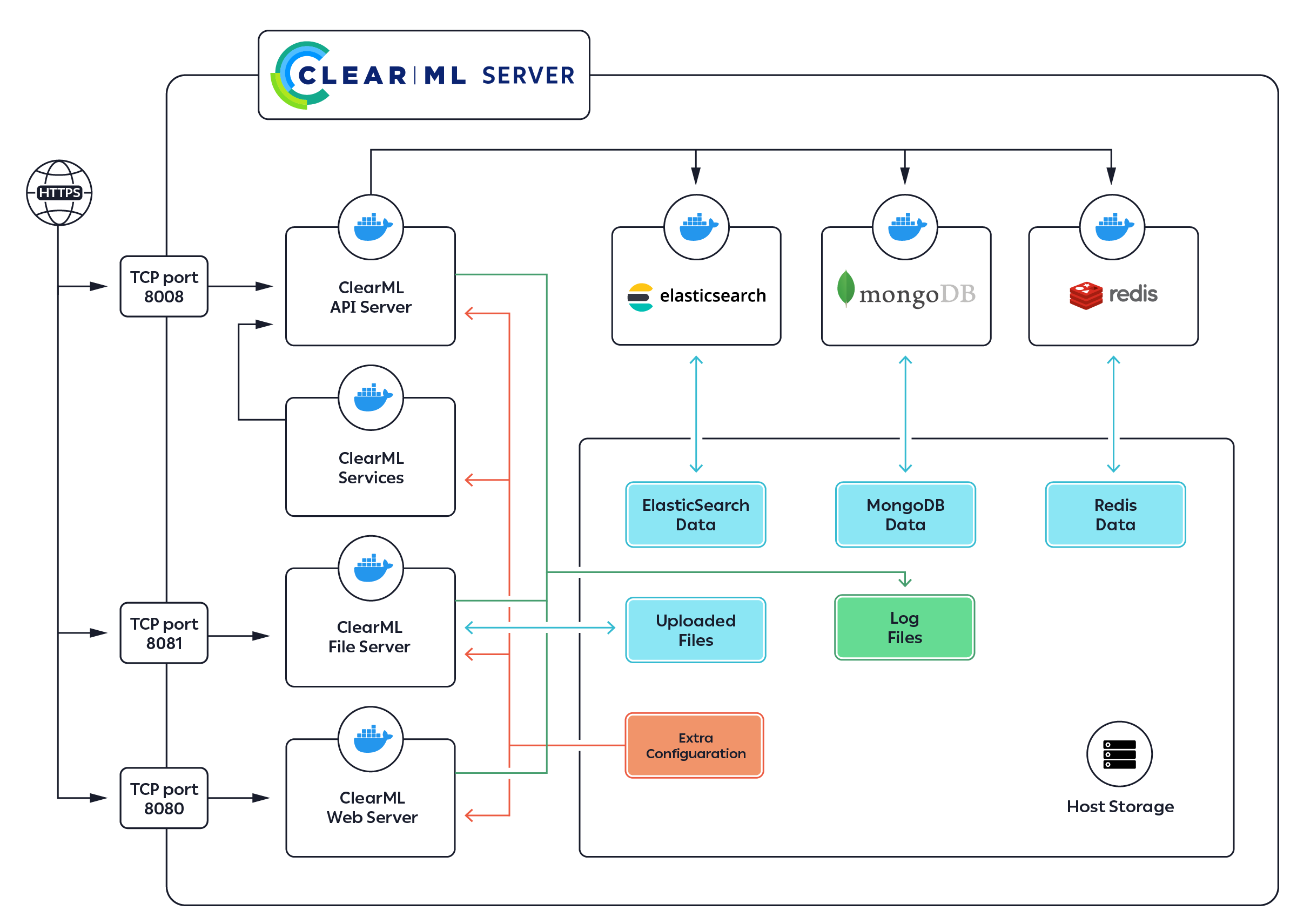
Hi, We have started to use clearml using the https://clear.ml/docs/latest/docs/deploying_clearml/upgrade_server_kubernetes_helm , and trying to understand ho...
4 years ago
Hi i'm trying to finalize a dataset, but although the finalize(auto_upload=True) completes successfully (see image) - But the dataset is still in an uploadin...
2 years ago
Hi, I have a question regarding the Dataset UI (chart helm version 4.1.3 )- WebApp: 1.6.0-213 • Server: 1.6.0-213 • API: 2.20. In order to create a Dataset y...
3 years ago
Hi, Newbe question in ClearML Data Assuming my files are already in a bucket on the cloud - What would be the best practice to create a dataset and register ...
3 years ago
Hi, Is there a way to instantiate a clearml-task while providing it a Dockerfile that it needs to build prior to executing the task? I know that there is a a...
2 years ago
Hi, Is it possible to run ffmpeg within clearml server as a multi processing (as in this example ?) assuming that the ffmpeg will run using a subprocess comm...
2 years ago
Hi, We are trying to understand when the auto-logging parameters configuration. from the https://github.com/allegroai/clearml/blob/master/examples/frameworks...
3 years ago
Hi We are getting the following error when we are trying to run a task on our on premis clearml-agent ( version 1.3.0) cloning: git@github.com:XXXX/sample.re...
3 years ago
Hi, I'm following the instructions for https://clear.ml/docs/latest/docs/guides/ide/remote_jupyter_tutorial . after > Launch interactive session [Y]/n? y I"m...
3 years ago
Hi, I've added external links to the a dataset In the UI I can see that the dataset has the property of Link count with the correct number. But where can I s...
3 years ago
Hi, We have a use case that we would like to upload a local folder into the cloud AS-IS - without compressing or breaking it up into chunks. I tried running ...
2 years ago
Hi, I'm looking for an example show how clearml dataset is consumed by sklearn pipeline or pytorch datapipe. e.g. since pytorch uses torch datasets, can we w...
3 years ago
Hi Another issue regarding dataset whenever preview ing the dataset (which is in a parquet tabular format) the browser automatically downloads a copy of the ...
3 years ago
Hi, I'm trying to run clearml-agent in docker mode - however I'm having trouble saving the artifacts. 2022-08-25 05:06:21,820 - clearml.storage - ERROR - Fai...
3 years ago
Hi, I'm running clearml==1.8.4rc0 When creating a Dataset with the following code - the dataset that is created includes ALL the files within the bucket and ...
2 years ago
Hi, I'm setting a USER PROPERTIES using the following code task.set_user_properties(MY_THRESHOLD={"type": int, "value": 0.85}, )Whet is the correct way to re...
3 years ago
Hi, Question regarding the command > clearml-agent list Were do you define the company and user that is running the Worker ? Looking at the https://clear.ml/...
3 years ago
Hi Community, We are having an issue connecting our clearml server via code When I connect via a web browser - there is no problem . When trying to connect v...
3 years ago
Hi, What would be the best way to save a pandas.DataFrame as an https://allegro.ai/clearml/docs/rst/references/clearml_python_ref/task_module/task_task.html?...
3 years ago
Hi, I'm running Dataset.list_datasets() (Version: 1.6.4) and I can't see all the Datasets that I see in the GUI. Any suggestions?
3 years ago
Hi, We have recently upgraded to > WebApp: 1.6.0-213 • Server: 1.6.0-213 • API: 2.20 I have some issues: I'm trying to delete a project - and although I don'...
3 years ago
Hi, Question regarding clearml-agent How do we delete a daemon? There is an option to stop a daemon service - but what is the method to delete a specific wor...
3 years ago
Hi, Is there a way to add the sdk https://clear.ml/docs/latest/docs/configs/clearml_conf#sdkgooglestorage parameters when setting the https://github.com/alle...
3 years ago
{kind=link}