




Hi @<1523701205467926528:profile|AgitatedDove14> !
Thank you again for coming back to me with your support!
- 👍 Thank you, I have noticed that (when using
model auto-update) different model versions (with their ownmodel_id) appear under "model_monitoring_eps" section of the serving service. - 👍 It's now clear to me that I was always accessing the static endpoint (that I created with
model add) with mycurlcommand.
I retested automatic model deployment with your suggestion of not usingmodel addat all, but instead onlymodel auto-updateto start the endpoint (since I precisely want automatic and not manual model deployment as you explained, in order to automatically select latest model with "released" tag).
Your solution looks very promising! 🏆 Unfortunately, I encounter following RPC error when using the curl command ( curl -X POST " None " -H "accept: application/json" -H "Content-Type: application/json" -d '{"url": " None "}' ):
{"detail":"Error processing request: <AioRpcError of RPC that terminated with:\n\tstatus = StatusCode.NOT_FOUND\n\tdetails = \"Request for unknown model: 'test_model_pytorch_auto/1' is not found\"\n\tdebug_error_string = \"UNKNOWN:Error received from peer ipv4:172.18.0.5:8001 {grpc_message:\"Request for unknown model: \\'test_model_pytorch_auto/1\\' is not found\", grpc_status:5, created_time:\"2023-11-22T09:47:10.632169727+00:00\"}\"\n>"}
This proves that the endpoint "test_model_pytorch_auto/1" effecively exists ( 🎉 ), because in contrast when I try to perform inference with an endpoint that doesn't exist, e.g. "test_model_pytorch_auto/2" (with curl -X POST " None " -H "accept: application/json" -H "Content-Type: application/json" -d '{"url": " None "}' ), I get following error message (see attached picture):
{"detail":"Error processing request: Model inference endpoint 'test_model_pytorch_auto/2' not found"}
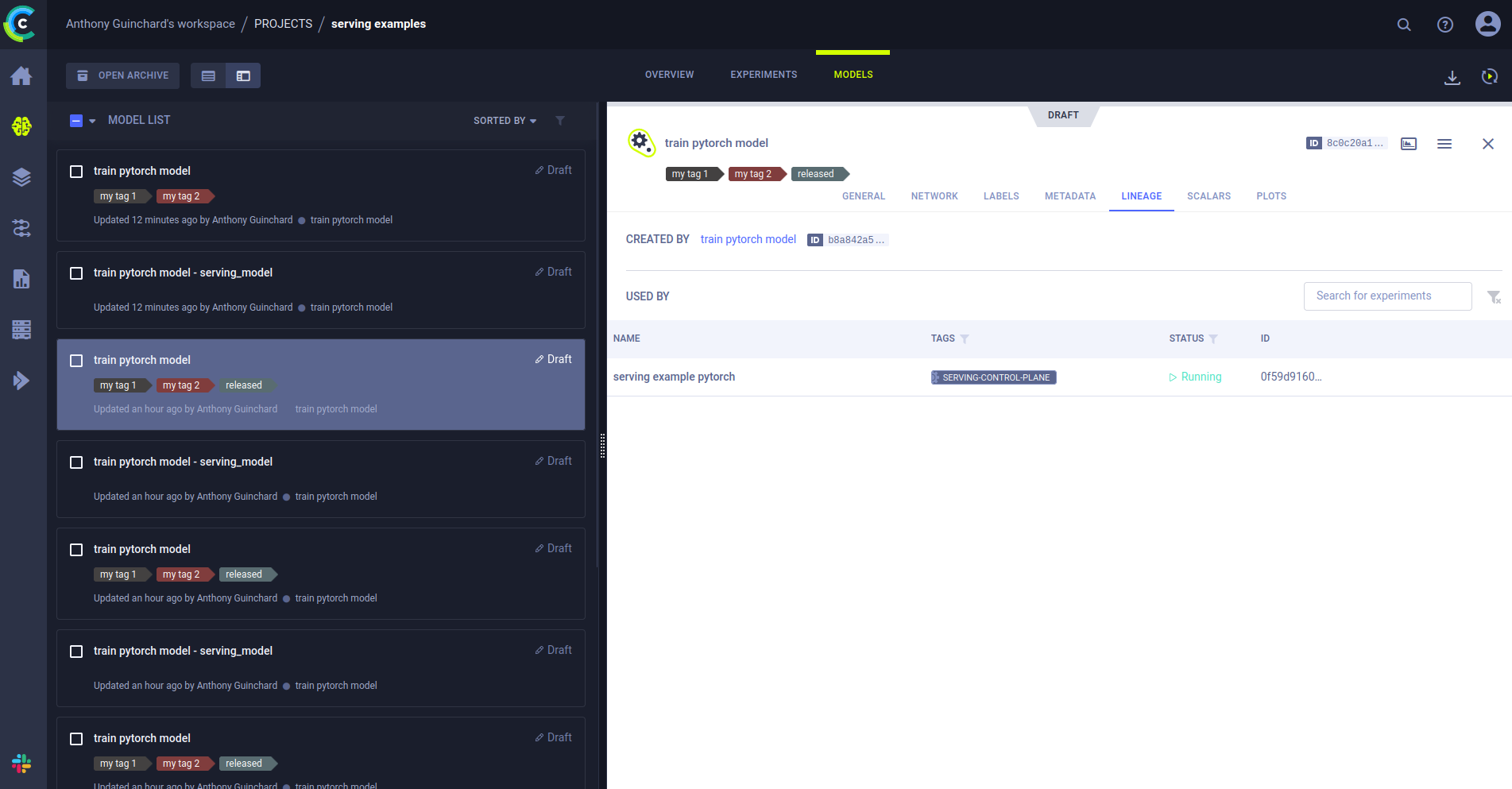
I don't have much insight into why the inference isn't working (since I'm using the exact same command you suggest and also the same one that's in the tutorial , and I'd be curious to know if you have any idea why the "test_model_pytorch_auto/1" model can't be found 🤔 . There is, after all, a link between the "train pytorch model" and the serving service when I look under the "LINEAGE" section of the model (see attached image).
Have you ever come across a similar case?
Thanks again in advance for your help! 🙇
Have a nice day ☀


Hi @<1523701205467926528:profile|AgitatedDove14> .,
Of course! The output of curl -X POST command is at least reassuring, it shows that the automatic endpoint works. As you say, the RPC error when sending request seems to be returned from the GPU backend.
Nothing gets printed in docker compose log when sending the curl -X POST , but beforehand following log is displayed for clearml-serving-triton container with among others WARNING: [Torch-TensorRT] - Unable to read CUDA capable devices. Return status: 35 , skipping model configuration auto-complete for 'test_model_pytorch_auto_1': not supported for pytorch backend and Inference Mode is disabled for model instance 'test_model_pytorch_auto_1' :
clearml-serving-triton | W1123 14:37:08.885296 53 pinned_memory_manager.cc:236] Unable to allocate pinned system memory, pinned memory pool will not be available: CUDA driver version is insufficient for CUDA runtime version
clearml-serving-triton | I1123 14:37:08.885337 53 cuda_memory_manager.cc:115] CUDA memory pool disabled
clearml-serving-triton | I1123 14:37:08.886498 53 model_lifecycle.cc:459] loading: test_model_pytorch_auto_1:1
clearml-serving-triton | WARNING: [Torch-TensorRT] - Unable to read CUDA capable devices. Return status: 35
clearml-serving-triton | I1123 14:37:09.081600 53 libtorch.cc:1983] TRITONBACKEND_Initialize: pytorch
clearml-serving-triton | I1123 14:37:09.081607 53 libtorch.cc:1993] Triton TRITONBACKEND API version: 1.10
clearml-serving-triton | I1123 14:37:09.081609 53 libtorch.cc:1999] 'pytorch' TRITONBACKEND API version: 1.10
clearml-serving-triton | I1123 14:37:09.081618 53 libtorch.cc:2032] TRITONBACKEND_ModelInitialize: test_model_pytorch_auto_1 (version 1)
clearml-serving-triton | W1123 14:37:09.081897 53 libtorch.cc:284] skipping model configuration auto-complete for 'test_model_pytorch_auto_1': not supported for pytorch backend
clearml-serving-triton | I1123 14:37:09.082100 53 libtorch.cc:313] Optimized execution is enabled for model instance 'test_model_pytorch_auto_1'
clearml-serving-triton | I1123 14:37:09.082103 53 libtorch.cc:332] Cache Cleaning is disabled for model instance 'test_model_pytorch_auto_1'
clearml-serving-triton | I1123 14:37:09.082104 53 libtorch.cc:349] Inference Mode is disabled for model instance 'test_model_pytorch_auto_1'
clearml-serving-triton | I1123 14:37:09.082106 53 libtorch.cc:444] NvFuser is not specified for model instance 'test_model_pytorch_auto_1'
clearml-serving-triton | I1123 14:37:09.082126 53 libtorch.cc:2076] TRITONBACKEND_ModelInstanceInitialize: test_model_pytorch_auto_1 (CPU device 0)
clearml-serving-triton | I1123 14:37:09.091582 53 model_lifecycle.cc:693] successfully loaded 'test_model_pytorch_auto_1' version 1
clearml-serving-triton | I1123 14:37:09.091667 53 server.cc:561]
clearml-serving-triton | +------------------+------+
clearml-serving-triton | | Repository Agent | Path |
clearml-serving-triton | +------------------+------+
clearml-serving-triton | +------------------+------+
clearml-serving-triton |
clearml-serving-triton | I1123 14:37:09.091684 53 server.cc:588]
clearml-serving-triton | +---------+---------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------+
clearml-serving-triton | | Backend | Path | Config |
clearml-serving-triton | +---------+---------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------+
clearml-serving-triton | | pytorch | /opt/tritonserver/backends/pytorch/libtriton_pytorch.so | {"cmdline":{"auto-complete-config":"true","min-compute-capability":"6.000000","backend-directory":"/opt/tritonserver/backends","default-max-batch-size":"4"}} |
clearml-serving-triton | +---------+---------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------+
clearml-serving-triton |
clearml-serving-triton | I1123 14:37:09.091701 53 server.cc:631]
clearml-serving-triton | +---------------------------+---------+--------+
clearml-serving-triton | | Model | Version | Status |
clearml-serving-triton | +---------------------------+---------+--------+
clearml-serving-triton | | test_model_pytorch_auto_1 | 1 | READY |
clearml-serving-triton | +---------------------------+---------+--------+
clearml-serving-triton |
clearml-serving-triton | Error: Failed to initialize NVML
clearml-serving-triton | W1123 14:37:09.092288 53 metrics.cc:571] DCGM unable to start: DCGM initialization error
clearml-serving-triton | I1123 14:37:09.092338 53 tritonserver.cc:2214]
clearml-serving-triton | +----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
clearml-serving-triton | | Option | Value |
clearml-serving-triton | +----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
clearml-serving-triton | | server_id | triton |
clearml-serving-triton | | server_version | 2.25.0 |
clearml-serving-triton | | server_extensions | classification sequence model_repository model_repository(unload_dependents) schedule_policy model_configuration system_shared_memory cuda_shared_memory binary_tensor_data statistics trace |
clearml-serving-triton | | model_repository_path[0] | /models |
clearml-serving-triton | | model_control_mode | MODE_POLL |
clearml-serving-triton | | strict_model_config | 0 |
clearml-serving-triton | | rate_limit | OFF |
clearml-serving-triton | | pinned_memory_pool_byte_size | 268435456 |
clearml-serving-triton | | response_cache_byte_size | 0 |
clearml-serving-triton | | min_supported_compute_capability | 6.0 |
clearml-serving-triton | | strict_readiness | 1 |
clearml-serving-triton | | exit_timeout | 30 |
clearml-serving-triton | +----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
clearml-serving-triton |
clearml-serving-triton | I1123 14:37:09.092982 53 grpc_server.cc:4610] Started GRPCInferenceService at 0.0.0.0:8001
clearml-serving-triton | I1123 14:37:09.093096 53 http_server.cc:3316] Started HTTPService at 0.0.0.0:8000
clearml-serving-triton | I1123 14:37:09.133947 53 http_server.cc:178] Started Metrics Service at 0.0.0.0:8002
Additionally, you can find attached the full docker compose log from the moment I entered docker-compose --env-file example.env -f docker-compose-triton.yml --verbose up ⤵ .
I am not really sure why this happens, maybe this is related to my GPU ( nvidia-smi -L indicates I have an NVIDIA GeForce RTX 4070 Ti :man-shrugging: ).
Thank you again for your precious insight! 😉
Best regards.
Hi @<1523701205467926528:profile|AgitatedDove14> !
Thank you for having a look at this log file 🙏 .
Effectively, the Triton backend was not able to load my model. I will investigate this issue that is surely related to my own GPU backend (GeForce RTX 4070 Ti), I suppose ClearML PyTorch example works for other users. I am not sure this is related to the fact the model is not correctly converted to TorchScript since I am directly testing ClearML PyTorch example (with no modifications, hence also including this line torch.jit.script(model).save(' serving_model.pt ') ) 🤔 . At least, the automatic endpoint exists! 😅 👍
That's weird that I have no problem to make inferences with static endpoint and however face this issue with automatic endpoint... 🙄
I tried to making use of docker-compose-triton-gpu.yml instead of docker-compose-triton.yml , but I still get the issue clearml-serving-triton | I1127 09:55:19.366794 57 libtorch.cc:349] Inference Mode is disabled for model instance 'test_model_pytorch_auto_1' .
Again, thank you very much for your help and insight! 🙇
Hi @<1523701205467926528:profile|AgitatedDove14> .,
Thanks a lot for your quick reply! 🙏 In fact, I am more interested in using the same endpoint with latest model version than effectively creating an endpoint on tagging.
Your statement makes sense, it seems that we have anyway to create an endpoint with model add prior to set up automatic model deployment with model auto-update . This seems to work since section "LINEAGE" under my latest trained model gets updated with information of my running Serving Service less than a minute after adding the tag "released" to it.
However, I am just confused because of two points:
- I notice that, in my Serving Service situated in the DevOps project, the "endpoints" section doesn't seem to get updated when I tag a new model with "released". In fact, the
model_idis still the one of the original model (d53b2257...) (and not the one of the latest trained model). - The tutorials (for sklearn and PyTorch ) explicitly say to perform inference with
test_model_pytorch_auto/1(i.e.,curl -X POST " [None](http://127.0.0.1:8080/serve/test_model_sklearn_auto/1) " -H "accept: application/json" -H "Content-Type: application/json" -d '{"x0": 1, "x1": 2}') (which doesn't work) instead oftest_model_pytorch(i.e.,curl -X POST " [None](http://127.0.0.1:8080/serve/test_model_pytorch) " -H "accept: application/json" -H "Content-Type: application/json" -d '{"x0": 1, "x1": 2}') (which works, but I am not sure it is using the latest trained model... ).
Can you confirm me that latest model is effectively used for inference even if "endpoints" section still seems to be configured with "model_id" of original trained model (d53b2257...)? (See screenshots below ⤵ )
Thank you again for your support.
Best regards!



Thanks for the logs @<1627478122452488192:profile|AdorableDeer85>
Notice that the log you attached means the preprocessing is executed and the GPU backend is returning an error.
Could you provide the log of the docker compose specifically the intersting part is the Triton container, I want to verify it loads the model properly

Hi @<1523701205467926528:profile|AgitatedDove14> ,
Just for verifying which model is actually called by the endpoint when using model auto-update for automatic model deployment I performed following steps with ClearML Serving PyTorch example :
- I modified the code of
train_pytorch_mnist.pyin thetrainfunction withtarget = torch.zeros(data.shape[0]).long()in order for the model to believe that every image corresponds to a "0". This way this model will always predict "0" and can be easily recognized later on when making inference. - I used this initial model to create the endpoint with
model addcommand. - Then, I used the command
model auto-updateto set up automatic model deployment - I removed
target = torch.zeros(data.shape[0]).long()trick line fromtrainfunction oftrain_pytorch_mnist.py, retrained the model and finally added tag "released" to it. This way, I had a second model that now predicts various numbers and not only "0". - I was then be able, by using the same
curl -X POSTcommand for inference (i.e.,curl -X POST "None" -H "accept: application/json" -H "Content-Type: application/json" -d '{"url": "None"}'), to see if the endpoint was now taking into account the new model or still the original one predicting only "0". - After waiting more than 20 minutes, I noticed that the value returned by the
curl -X POSTcommand was still always "0" (see picture below ⤵ ), meaning that the endpoint is still pointing towards the original model and NOT the new one with tag "released"... This actually makes sense (and that's what I was afraid of) sincemodel_idunder "endpoints" section of the Serving Service doesn't get updated and is still the one of the original model (and NOT the latest one with "released" tag).
I guess model auto-update doesn't work the way I was expecting it to work. Do you have any thoughts on what I could do wrong for automatic model deployment not to work and not being able to use the endpoint with latest model without having to recreate a new endpoint for each latest model?
Thank you again very much for your precious insight! :man-bowing:
Okay, so that's surely the reason why the model is not found, I will investigate that, thank you again for your insight! 🙏
I notice that, in my Serving Service situated in the DevOps project, the "endpoints" section doesn't seem to get updated when I tag a new model with "released".
It takes it a few minutes (I think 5 min is the default) to update.
Notice that you need to add the model with
model auto-update --engine triton --endpoint "test_model_pytorch_auto" ...
Not with model add (if for some reason that does not work please let me know)
No need to pass the model version i.e. 1 you can just address the "main" endpoint and get the latest version:
so curl -X POST "[None](http://127.0.0.1:8080/serve/test_model_pytorch)" will be the latest model and /1 /2 will be specific versions (i.e. previous versions)
Regarding the DevOps project, when creating the serving session add --project to change it
clearml-serving create --project <serving project>
See None
Hi @<1636175432829112320:profile|PlainSealion45>
- I used this initial model to create the endpoint with
model add
command.
I think that the initial model needs to be added with model auto-aupdate Not with model add
basically do not call model add - this is static, always using the model ID specified (you can deploy new models with manually callign model add on the same endpoint and specifying diffrent model ID , but again manual)
To Automatically have the models change - and always select the latest one, just call:
learml-serving --id <service_id> model auto-update --tags release --engine triton --endpoint "test_model_pytorch_auto" --preprocess "examples/pytorch/preprocess.py" --name "train pytorch model" --project "serving examples" --max-versions 2 --input-size 1 28 28 --input-name "INPUT__0" --input-type float32 --output-size -1 10 --output-name "OUTPUT__0" --output-type float32
This will take the latest model with the Name "train pytorch model" and the tag "release" from the project "serving examples"
I assume it never worked because you started the endpoint with model add and not auto-update
Notice that in one of your screenshots you have "model_monitoring_eps" with multiple versions of the same endpoint: "test_model_pytorch_auto/2" and "test_model_pytorch_auto/3" which means it created multiple endpoints for diffrent versions, you can also see that each version is using a different model ID
https://clearml.slack.com/files/U066EHAKE9F/F06760GG6NL/2023-11-20_clearmlautomaticmo[…]model_monitoring_eps_monitoredmodelswithtag__released_.png
![https://clearml.slack.com/files/U066EHAKE9F/F06760GG6NL/2023-11-20_clearmlautomaticmo[…]model_monitoring_eps_monitoredmodelswithtag__released_.png](https://clearml.slack.com/files/U066EHAKE9F/F06760GG6NL/2023-11-20_clearmlautomaticmodeldeployment_3_servingservice_model_monitoring_eps_monitoredmodelswithtag__released__.png){kind=link}
But your curl code is Not accessing the "test_model_pytorch_auto" it accesses the Static endpoint you added witn model add "test_model_pytorch"" None " ...
So basically just try: curl " None "... and curl " None ..." etc
Yes! That's exactly what I meant, as you can see the Triton backend was not able to load your model. I'm assuming because it was Not converted to torch script, like we do in the original example
https://github.com/allegroai/clearml-serving/blob/6c4bece6638a7341388507a77d6993f447e8c088/examples/pytorch/train_pytorch_mnist.py#L136
Thank you so much for your reply Martin!
It's clear to me now.
Let's see if this works! I will try waiting those 5 minutes at the beginning of next week and let you know if I can obtain an updated endpoint with the new model id of the latest trained model!
Have a nice weekend!
Best regards.
Hi @<1636175432829112320:profile|PlainSealion45>
I am trying to automatically generate an online endpoint for inference when manually adding tag
released
to a model.
So the "automatic" here means that the model endpoint will be updated with the latest model, but not that a new endpoint will be created.
Does that make sense ?
To add a new endpoint on Tagging a model, you should combine it with ModelTrigger and have a fucntion that calls the clearml-serving to create a new endpoint.
wdyt?
Well, after testing, I observed two things:
- When using automatic model deployment and training several models to which tag "released" was added, the
model_idin the "endpoints" section of the Serving Service persistently presents the ID of the initial model that was used to create the endpoint (and NOT the one of the latest trained model) (see first picture below ⤵ ). This is maybe the way it is implemented in ClearML, but a bit non-intuitive since, when using automatic model deployment, we would expect the endpoint to be pointing to the latest trained model with tag "released". Now, I suppose this endpoint is anyway pointing to the latest trained model with tag "released", even if themodel_iddisplayed is still the one of the initial model. Maybe ClearML Serving is implemented that way :man-shrugging: . - After using the command
model auto-update, I trained several models and successively tagged them with "released". I noticed that, each time after training and tagging a new model, only latest trained model with tag "released" presents a link to the Serving Service under its "LINEAGE" tab. All other models that were previously trained and added tag "released" don't have this link under the "LINEAGE" tab, except the very initial model that was used to create the endpoint (see other pictures below ⤵ ). This makes me hope that the endpoint is effectively pointing towards the latest trained model with tag "released" 🙏 .



. I am not sure this is related to the fact the model is not correctly converted to TorchScript
Because Triton Only supports TorchScript (Not torch models) 🙂