👋 Hi everyone!
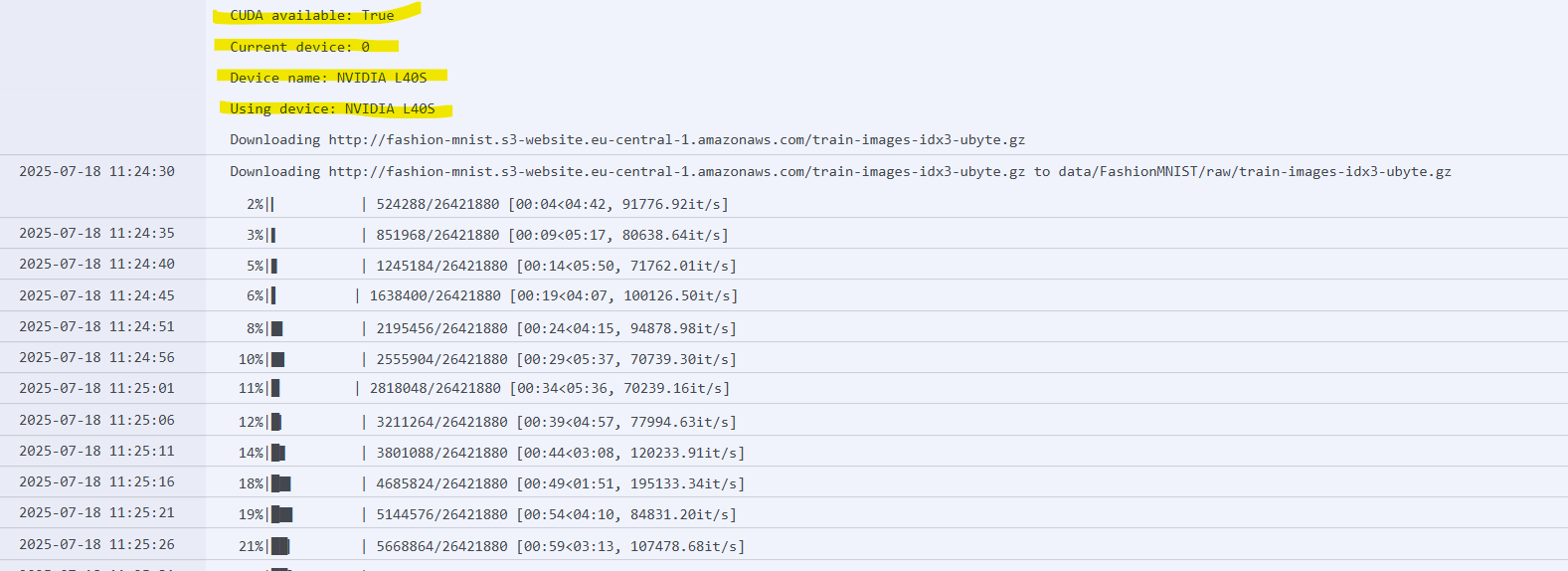
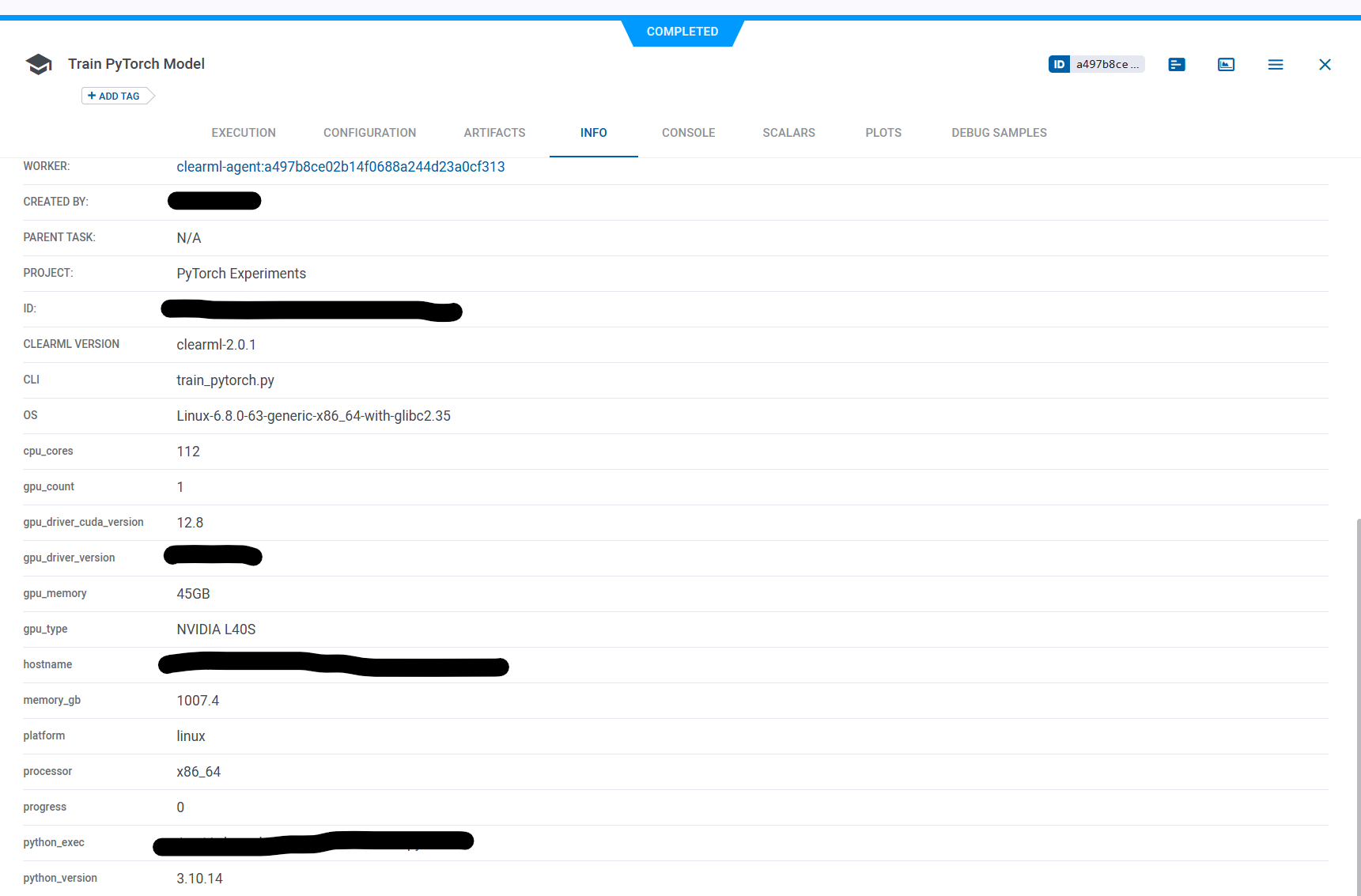
We’re facing an issue where ClearML workloads run successfully on our Kubernetes cluster (community edition), but never utilize the GPU — despite being scheduled on worker13 which has NVIDIA L40S GPUs. The workload logs correctly detect CUDA and GPU details (via torch.cuda ), but nvidia-smi shows no active processes during execution, and the ClearML GPU monitor remains empty. We’ve verified NVIDIA drivers and plugins, used GPU-heavy PyTorch tasks, set proper node selectors and tolerations, mounted libnvidia-ml.so , set runtimeClassName: nvidia , and downgraded the agent to 1.9.2. Despite all this, the tasks always run on CPU. I’m new to ClearML, so any guidance is appreciated. Attaching the clearml-agent-values.yaml file for reference.
# -- Global parameters section
global:
# -- Images registry
imageRegistry: "docker.io"
# -- Private image registry configuration
imageCredentials:
# -- Use private authentication mode
enabled: false
# -- If this is set, chart will not generate a secret but will use what is defined here
existingSecret: ""
# -- Registry name
registry: docker.io
# -- Registry username
username: someone
# -- Registry password
password: pwd
# -- Email
email: someone@host.com
# -- ClearMl generic configurations
clearml:
# -- If this is set, chart will not generate a secret but will use what is defined here
existingAgentk8sglueSecret: ""
# -- Agent k8s Glue basic auth key
agentk8sglueKey: ""
# -- Agent k8s Glue basic auth secret
agentk8sglueSecret: ""
# -- If this is set, chart will not generate a secret but will use what is defined here
existingClearmlConfigSecret: ""
# The secret should be defined as the following example
#
# apiVersion: v1
# kind: Secret
# metadata:
# name: secret-name
# stringData:
# clearml.conf: |-
# sdk {
# }
# -- ClearML configuration file
clearmlConfig: |-
api {
web_server:
api_server:
files_server:
credentials: {
access_key: "",
secret_key: ""
}
}
# -- This agent will spawn queued experiments in new pods, a good use case is to combine this with
# GPU autoscaling nodes.
#
agentk8sglue:
# -- Glue Agent image configuration
image:
registry: ""
repository: "allegroai/clearml-agent-k8s-base"
tag: "1.24-21"
runtimeClassName: nvidia
# -- Glue Agent number of pods
replicaCount: 1
# -- Glue Agent pod resources
resources:
limits:
nvidia.com/gpu: 1
#cpu: 4
#memory: 8Gi
requests:
nvidia.com/gpu: 1
#cpu: 500m
#memory: 512Mi
# -- Glue Agent pod initContainers configs
initContainers:
# -- Glue Agent initcontainers pod resources
resources: {}
# -- Add the provided map to the annotations for the ServiceAccount resource created by this chart
serviceAccountAnnotations: {}
# -- If set, do not create a serviceAccountName and use the existing one with the provided name
serviceExistingAccountName: ""
# -- Check certificates validity for evefry UrlReference below.
clearmlcheckCertificate: true
# -- Reference to Api server url
apiServerUrlReference: "
"
# -- Reference to File server url
fileServerUrlReference: "
"
# -- Reference to Web server url
webServerUrlReference: "
"
# -- default container image for ClearML Task pod
defaultContainerImage: pytorch/pytorch:latest
# -- ClearML queue this agent will consume. Multiple queues can be specified with the following format: queue1,queue2,queue3
queue: Workloads_Test
# -- if ClearML queue does not exist, it will be create it if the value is set to true
createQueueIfNotExists: false
# -- labels setup for Agent pod (example in values.yaml comments)
labels: {}
# schedulerName: scheduler
# -- annotations setup for Agent pod (example in values.yaml comments)
annotations: {}
# key1: value1
# -- Extra Environment variables for Glue Agent
#extraEnvs: []
# - name: PYTHONPATH
# value: "somepath"
# -- container securityContext setup for Agent pod (example in values.yaml comments)
podSecurityContext: {}
# runAsUser: 1001
# fsGroup: 1001
# -- container securityContext setup for Agent pod (example in values.yaml comments)
containerSecurityContext: {}
# runAsUser: 1001
# fsGroup: 1001
# -- additional existing ClusterRoleBindings
additionalClusterRoleBindings: []
# - privileged
# -- additional existing RoleBindings
additionalRoleBindings: []
# - privileged
# -- nodeSelector setup for Agent pod (example in values.yaml comments)
nodeSelector:
kubernetes.io/hostname: worker13
nvidia.com/gpu.product: NVIDIA-L40S
# fleet: agent-nodes
# -- tolerations setup for Agent pod (example in values.yaml comments)
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
# -- affinity setup for Agent pod (example in values.yaml comments)
affinity: {}
# -- volumes definition for Glue Agent (example in values.yaml comments)
volumes:
- name: config-volume
emptyDir: {}
- name: nvidia-libs
hostPath:
path: /usr/lib/x86_64-linux-gnu
type: DirectoryOrCreate
volumeMounts:
- mountPath: /root/clearml.conf
name: config-volume
subPath: clearml.conf
- mountPath: /usr/lib/x86_64-linux-gnu/libnvidia-ml.so.1
name: nvidia-libs
subPath: libnvidia-ml.so.570.158.01
readOnly: true
extraEnvs:
- name: CLEARML_AGENT_UPDATE_VERSION
value: "==1.9.2"
# - name: "yourvolume"
# nfs:
# server: 192.168.0.1
# path: /var/nfs/mount
# -- volume mounts definition for Glue Agent (example in values.yaml comments)
#volumeMounts: []
# - name: yourvolume
# mountPath: /yourpath
# subPath: userfolder
# -- file definition for Glue Agent (example in values.yaml comments)
fileMounts: []
# - name: "integration.py"
# folderPath: "/mnt/python"
# fileContent: |-
# def get_template(*args, **kwargs):
# print("args: {}".format(args))
# print("kwargs: {}".format(kwargs))
# return {
# "template": {
# }
# }
# -- base template for pods spawned to consume ClearML Task
basePodTemplate:
runtimeClassName: nvidia
defaultContainerImage: nvidia/cuda:12.4.0-runtime-ubuntu20.04
# -- labels setup for pods spawned to consume ClearML Task (example in values.yaml comments)
labels: {}
# schedulerName: scheduler
# -- annotations setup for pods spawned to consume ClearML Task (example in values.yaml comments)
annotations: {}
# key1: value1
# -- initContainers definition for pods spawned to consume ClearML Task (example in values.yaml comments)
initContainers: []
# - name: volume-dirs-init-cntr
# image: busybox:1.35
# command:
# - /bin/bash
# - -c
# - >
# /bin/echo "this is an init";
# -- schedulerName setup for pods spawned to consume ClearML Task
schedulerName: ""
# -- volumes definition for pods spawned to consume ClearML Task (example in values.yaml comments)
# volumes:
# - name: nvidia-libs
# hostPath:
# path: /usr/lib/x86_64-linux-gnu # Confirmed path from your output
#volumeMounts:
# - mountPath: /usr/lib/x86_64-linux-gnu/libnvidia-ml.so.1 # Symlink target
# name: nvidia-libs
# subPath: libnvidia-ml.so.570.158.01 # Actual file from your output
#readOnly: true
#env:
# - name: LD_LIBRARY_PATH
# value: "/usr/lib/x86_64-linux-gnu:${LD_LIBRARY_PATH}"
# - name: "yourvolume"
# nfs:
# server: 192.168.0.1
# path: /var/nfs/mount
# -- volume mounts definition for pods spawned to consume ClearML Task (example in values.yaml comments)
#volumeMounts: []
# - name: yourvolume
# mountPath: /yourpath
# subPath: userfolder
# -- file definition for pods spawned to consume ClearML Task (example in values.yaml comments)
#fileMounts: []
# - name: "mounted-file.txt"
# folderPath: "/mnt/"
# fileContent: |-
# this is a test file
# with test content
# -- environment variables for pods spawned to consume ClearML Task (example in values.yaml comments)
#env: []
# # to setup access to private repo, setup secret with git credentials:
# - name: CLEARML_AGENT_GIT_USER
# value: mygitusername
# - name: CLEARML_AGENT_GIT_PASS
# valueFrom:
# secretKeyRef:
# name: git-password
# key: git-password
# - name: CURL_CA_BUNDLE
# value: ""
# - name: PYTHONWARNINGS
# value: "ignore:Unverified HTTPS request"
# -- resources declaration for pods spawned to consume ClearML Task (example in values.yaml comments)
resources:
limits:
nvidia.com/gpu: 1
#cpu: 4
#memory: 8Gi
requests:
nvidia.com/gpu: 1
#cpu: 4
#memory: 8Gi
# limits:
# nvidia.com/gpu: 1
# -- priorityClassName setup for pods spawned to consume ClearML Task
priorityClassName: ""
# -- nodeSelector setup for pods spawned to consume ClearML Task (example in values.yaml comments)
nodeSelector:
kubernetes.io/hostname: worker11
nvidia.com/gpu.product: NVIDIA-L40S
# fleet: gpu-nodes
# -- tolerations setup for pods spawned to consume ClearML Task (example in values.yaml comments)
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
# - key: "nvidia.com/gpu"
# operator: Exists
# effect: "NoSchedule"
# -- affinity setup for pods spawned to consume ClearML Task
affinity: {}
# -- securityContext setup for pods spawned to consume ClearML Task (example in values.yaml comments)
podSecurityContext: {}
# runAsUser: 1001
# fsGroup: 1001
# -- securityContext setup for containers spawned to consume ClearML Task (example in values.yaml comments)
containerSecurityContext: {}
# runAsUser: 1001
# fsGroup: 1001
# -- hostAliases setup for pods spawned to consume ClearML Task (example in values.yaml comments)
hostAliases: []
# - ip: "127.0.0.1"
# hostnames:
# - "foo.local"
# - "bar.local"
# -- Sessions internal service configuration
sessions:
# -- Enable/Disable sessions portmode WARNING: only one Agent deployment can have this set to true
portModeEnabled: false
# -- specific annotations for session services
svcAnnotations: {}
# -- service type ("NodePort" or "ClusterIP" or "LoadBalancer")
svcType: "NodePort"
# -- External IP sessions clients can connect to
externalIP: 0.0.0.0
# -- starting range of exposed NodePorts
startingPort: 30000
# -- maximum number of NodePorts exposed
maxServices: 20